Ever Heard of This Mysterious Thing Called RAG?

Have you ever sat in a meeting where someone casually drops the term RAG, and everyone just nods like it’s common knowledge? Meanwhile, you're sitting there thinking, “Wait… what is RAG?” Yeah, that was me too. So I did some digging — and now I'm here to share what I found.
This post gives you a super high-level overview of RAG (short for Retrieval-Augmented Generation), and why it might be the magic behind that smart AI bot someone just demoed.
Meet My Shiny New AI Chat Bot ✨
I recently built a chatbot that helps you learn about your teammates — even the ones you've never met. Pretty neat, right?

Just ask it: "Who’s John Doe?" and boom — it pulls up all the relevant info in seconds.
But hold up — how does it even know who John Doe is? He’s not famous. He’s not on Wikipedia. And yet, the bot responds like it’s been following his career for years.
The secret? You guessed it: RAG.
So… What Is RAG, Exactly?
RAG stands for Retrieval-Augmented Generation — and the name kind of gives it away.
In plain English: before an LLM (like ChatGPT) gives you a response, it retrieves some relevant context and augments the prompt with that data.
Let’s peek under the hood of our chatbot to see what’s going on.
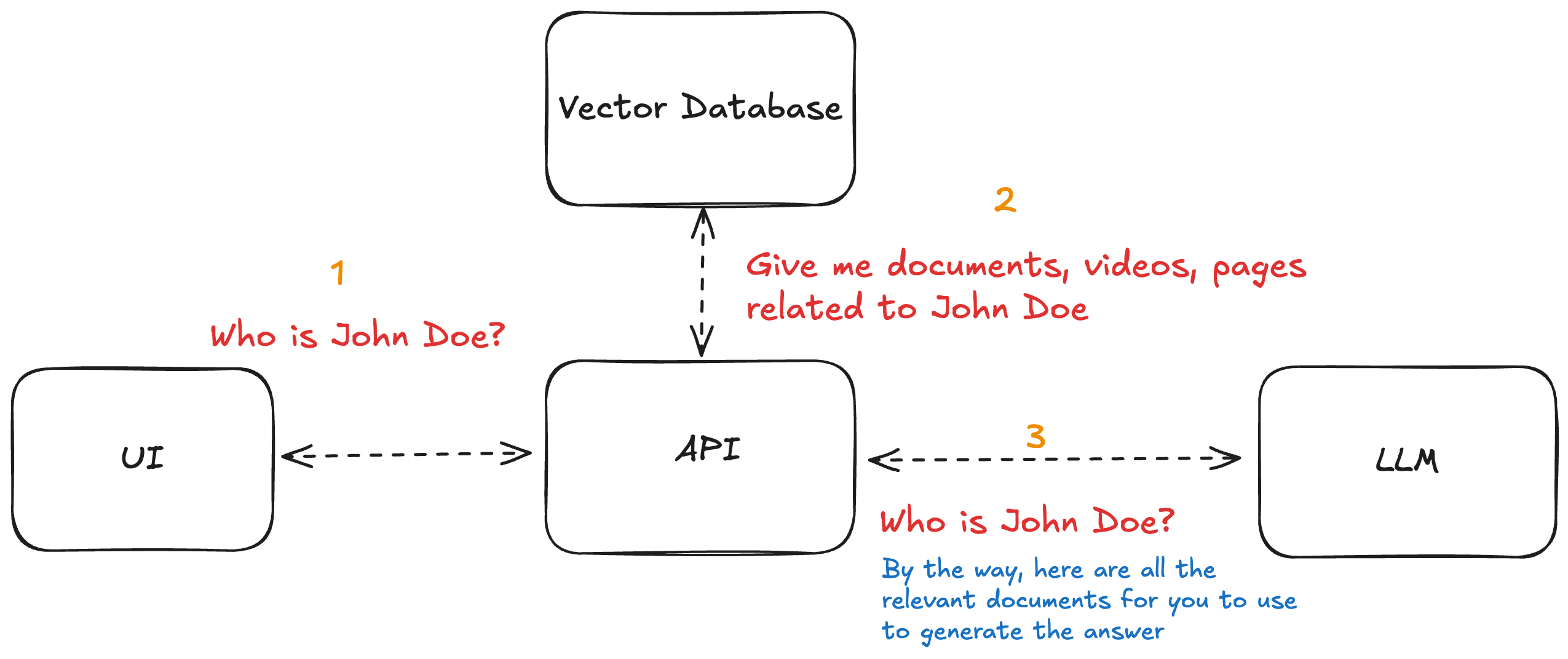
Ah-ha! There’s another player in this game: the Vector Database.
Vector Databases — The Brain Behind the Bot 🧠
A vector database (like Weaviate or Pinecone) doesn’t just do keyword matching — it understands the meaning behind your query. This is what we call semantic search.
Let’s say you search for “dog.” You won’t just get results that contain the word “dog.” You’ll also get content about chihuahuas or yorkies, because semantically, those are close matches.
So when you ask the bot “Who is John Doe?”, the flow looks something like this:
- The query is semantically matched against stored content in the vector DB.
- Relevant info about John is fetched.
- That info is injected into the LLM prompt.
- The LLM uses that context to craft a smart response.
Boom — now the bot sounds like it’s besties with John Doe.
How Do You Get Content Into the Vector Database?
Great question. It all starts with something called embeddings — basically, secret codes that the LLM understands.
The simplest way to generate them is by using text. First, turn your source (like documents, transcripts, or notes) into plain text. Then, feed that text into an embedding model — like OpenAIEmbeddings.
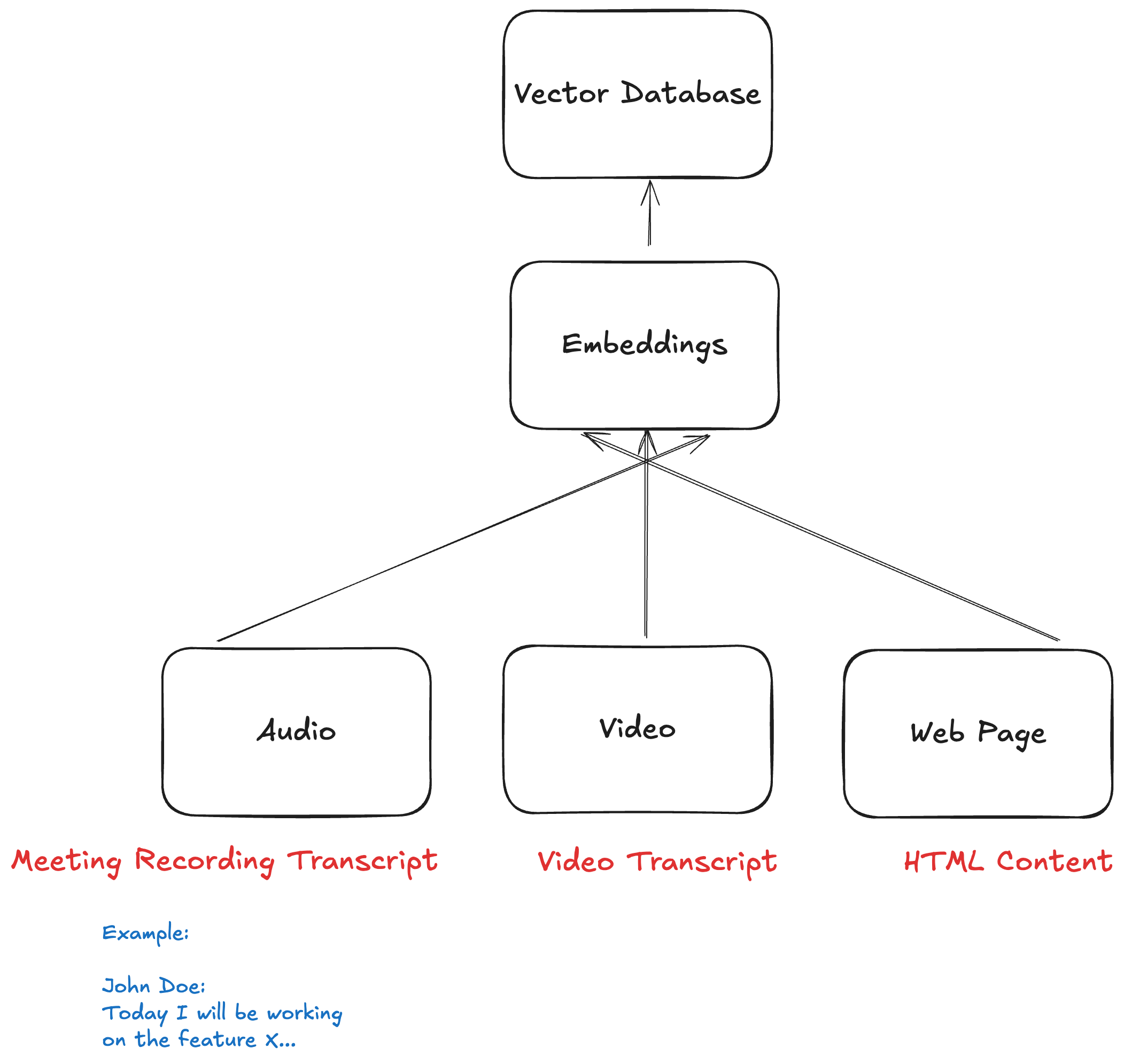
These embeddings get stored in the vector database. Later, when a user asks a question, the system retrieves relevant content based on those embeddings and feeds it to the LLM.
Simple? Sort of. Powerful? Definitely.
Wrapping Up
To recap:
- RAG is all about fetching relevant content and letting the LLM use it to sound like a genius.
- It relies on a vector database to understand the meaning of queries.
- And behind the scenes, embeddings make the whole thing tick.
If you’ve ever wondered how AI chatbots actually work, RAG is a big part of the answer.
Thanks for reading! If you liked this, you might also enjoy:
How I Fixed a Weird Flexbox Bug (and Saved My Sanity)
Until next time — happy coding! 🧑💻