Building Reliable Background Tasks for AI Agents - Timer-Based Scheduling vs Distributed Queues

Building Reliable Background Tasks for AI Agents - Timer-Based Scheduling vs Distributed Queues
AI agents are quickly moving beyond "answering questions" and into executing long-running workflows.
A modern AI agent is now expected to:
- remind users tomorrow
- follow up in 3 days
- retry failed operations
- monitor conditions over time
- schedule recurring actions
- wait for external events
- continue workflows after restarts
At some point, every serious AI product needs background task architecture.
And this is where architectural tradeoffs begin to matter.
This article walks through production-grade background task architecture for AI agents:
- timer-based schedulers vs distributed queues
- why duplicate processing happens in multi-worker environments
- how queue systems solve distributed coordination
- how Redis and persistent databases fit together
- why queue state should be treated as ephemeral
- how LLMs schedule tasks through tools
- why scheduling logic belongs in shared infrastructure
- how tool calls can become UI widgets instead of plain text confirmations
Why Background Tasks Matter for AI Agents
Traditional web applications are request-response driven.
AI agents are different.
Users increasingly expect agents to behave asynchronously:
"Remind me tomorrow morning"
"Follow up with this lead in 2 hours"
"Retry this import later"
"Check if the customer replied"
"Notify me when the document changes"
This means your agent must survive:
- process restarts
- deployments
- crashes
- scaling events
- delayed execution
- long waiting periods
This is not just an infrastructure concern anymore.
Background task orchestration is becoming part of the core AI product architecture.
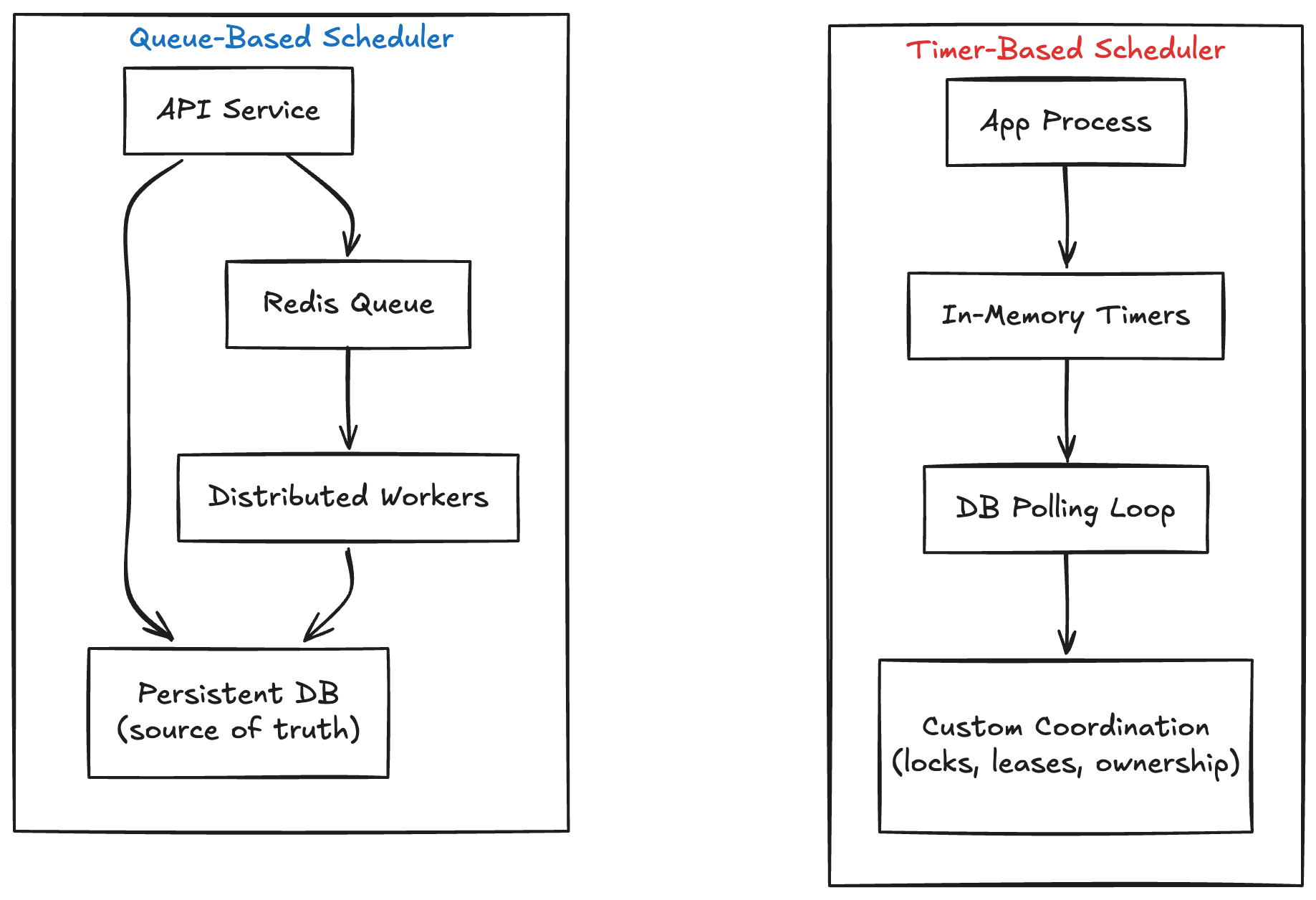
Two Common Approaches to Scheduling Tasks
There are two major approaches developers usually consider first:
- In-memory timers (
setTimeout,setInterval, scheduler loops) - Queue-based schedulers (Redis-backed queues, workflow engines, distributed workers)
Both are valid.
The correct choice depends heavily on the operational model of your AI agent.
Timer-Based Scheduling
The simplest implementation usually looks like this:
setTimeout(async () => {
await sendReminder(userId);
}, delay);
Or:
setInterval(async () => {
await pollForUpdates();
}, 1000 * 60);
This approach is more powerful than many developers initially assume.
It is a proven way to build schedulers and can work very well when:
- running a single instance
- running locally on the user's machine
- building internal tools
- minimizing infrastructure overhead
- maintaining full control over scheduling semantics
For example, OpenClaw Github uses this general architecture approach.
That said, there is an important contextual detail:
OpenClaw primarily serves a single user and runs on the user's own machine.
That dramatically reduces distributed systems complexity compared to a remote AI platform serving hundreds or thousands of users across many worker nodes.
The Real Tradeoff With Timer-Based Schedulers
A timer-based scheduler is a perfectly valid architectural choice in many systems.
The tradeoff is not that the approach is "wrong".
The tradeoff is that once your system becomes distributed, you must implement coordination mechanisms yourself:
- distributed locks
- leases
- heartbeat recovery
- stuck task recovery
- ownership claiming
- duplicate execution protection
Whether this is acceptable depends heavily on the deployment model of your AI agent.
The Multi-Worker Problem
Imagine your application runs in Kubernetes with 3 replicas:
worker-pod-1
worker-pod-2
worker-pod-3
Each pod runs this scheduler:
setInterval(async () => {
const jobs = await findPendingJobs();
for (const job of jobs) {
await processJob(job);
}
}, 5000);
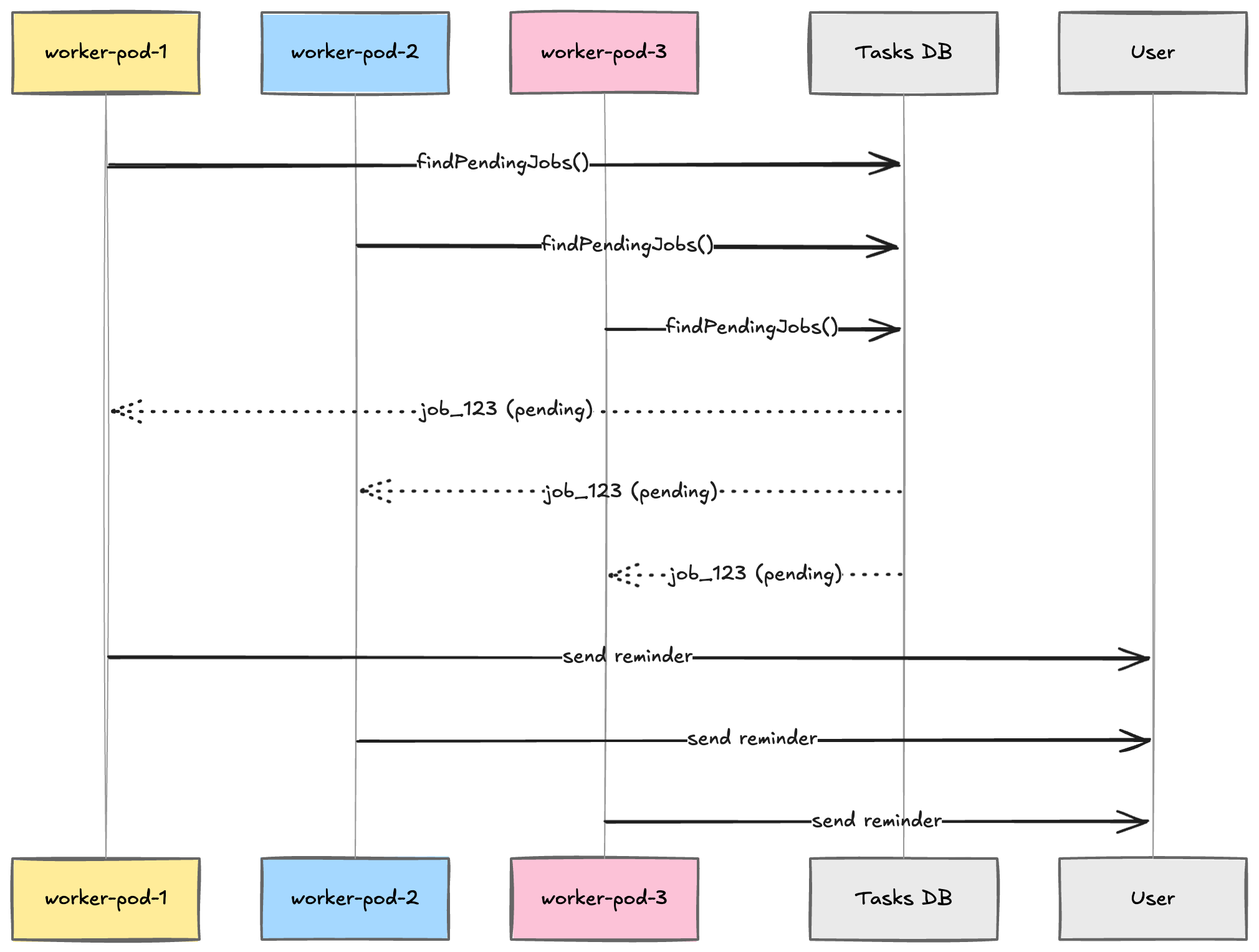
Now all 3 workers poll the database simultaneously.
And all 3 may find the same pending job.
Result:
User receives the same reminder 3 times
This is one of the core coordination challenges in distributed schedulers.
Queue-Based Scheduling
Queue-based schedulers become especially attractive once your AI agent evolves into a distributed multi-tenant platform.
Instead of implementing distributed coordination yourself, the queue infrastructure becomes the coordination mechanism.
Workers consume jobs directly from the queue:
worker → claims job → processes job → acknowledges completion
Now even if you have:
worker-pod-1
worker-pod-2
worker-pod-3
the queue system guarantees that a given job is claimed by only one worker at a time.
This is possible because systems like Redis support atomic operations.
The queue itself becomes the concurrency control mechanism.
That removes a large category of distributed coordination work from your application code.
Popular Queue Systems by Ecosystem
Different ecosystems typically use different queue technologies.
For example:
Node.js / TypeScript
Common choices include:
- BullMQ
- Bee-Queue
- Agenda
- RabbitMQ-based workers
BullMQ is especially popular in the Node.js ecosystem because it provides:
- delayed jobs
- retries
- concurrency control
- worker distribution
- Redis-backed atomicity
with relatively low operational overhead.
Python
Common choices include:
- Celery
- RQ
- Dramatiq
- Huey
Celery is one of the most established distributed task systems in the Python ecosystem and is heavily used in production AI infrastructure.
Especially in systems involving:
- FastAPI
- Django
- ML pipelines
- model execution workers
- async processing infrastructure
The important architectural idea is not the specific library.
The important idea is:
distributed workers need a reliable coordination mechanism
Why Redis Works Well for Distributed Queues
Redis is particularly good for distributed queues because operations like:
pop next job
mark claimed
move to processing
can happen atomically.
Most modern queue systems heavily rely on Redis atomicity under the hood.
This is exactly the kind of primitive distributed schedulers need.
Instead of implementing distributed locking yourself, you inherit battle-tested queue semantics.
How Redis Atomicity Makes Queue Coordination Possible
The important Redis idea behind distributed queues is that a command is executed atomically from the perspective of other Redis clients.
Redis processes commands through a single-threaded command execution model for the main data path. That means while Redis is executing one command, another client's command does not interleave halfway through it.
So if a queue uses a Redis command that removes an item from one list and adds it to another structure, that operation is not seen by other workers as two half-finished steps.
For example, a queue can model job claiming like this:
pending queue -> move job -> active/processing set
The key detail is that the read and write happen as one indivisible operation.
That is why three workers can all ask Redis for the next job, but only one worker receives a specific job. Once Redis gives that job to worker A, the job has already been removed or marked as claimed before worker B or worker C can receive it.
This is different from a naive database polling loop like:
const job = await findNextPendingJob();
await markJobAsProcessing(job.id);
In that version, the read and write are two separate application-level steps. Another worker can read the same pending job before the first worker marks it as processing. That gap is where duplicate execution comes from.
Redis queues avoid this by using atomic primitives. Depending on the queue implementation, this can involve commands that move data atomically, sorted set operations, locks with expiration, or a combination of Redis data structures.
For more complex workflows, queues often use Lua scripts.
A Lua script lets the queue package multiple Redis operations into one atomic unit. Redis executes the entire script without interleaving other commands in the middle. That allows a queue to safely perform logic like:
1. check whether the job is available
2. remove it from the delayed or waiting set
3. add it to the active set
4. assign lock metadata
5. return the claimed job to exactly one worker
From the worker's perspective, this looks simple:
worker asks for job -> Redis atomically claims job -> worker processes job
But internally, the queue may be doing several reads and writes safely in one Redis-side operation.
That is the real reason Redis-backed queues work well in multi-pod environments. They do not merely store jobs. They provide atomic coordination primitives that prevent multiple workers from claiming the same work at the same time.
Important Reality Check - Queue State Is Ephemeral
One mistake I see often:
treating the queue itself as the source of truth
This is dangerous.
Queues are operational infrastructure.
They are not durable business state.
Queue jobs can disappear because of:
- Redis flushes
- infrastructure mistakes
- persistence configuration
- accidental cleanup
- crashes
- failovers
- retention policies
Your business workflow should not depend exclusively on queue existence.
Recommended Architecture - Persistent DB + Queue Infrastructure
The safer architecture is:
Persistent DB = source of truth
Queue system = execution mechanism
For example:
CouchDB
stores:
- scheduled tasks
- lifecycle state
- retry metadata
- ownership
- timestamps
- audit history
Queue system
handles:
- delayed execution
- worker distribution
- retries
- concurrency
This separation becomes extremely important later when debugging production incidents.
You can always reconstruct queue state from persistent storage if needed.
Example Data Model for AI Agent Tasks
A scheduled task record might look like this:
{
"_id": "task_123",
"user_id": "user_456",
"status": "scheduled",
"timezone": "America/Edmonton",
"nextRun": "2026-05-20T15:00:00Z",
"type": "follow_up",
"payload": {
"message": "Follow up with the customer"
},
"createdAt": "2026-05-16T12:00:00Z",
"updatedAt": "2026-05-16T12:00:00Z",
"queueJobId": "job-789"
}
Then your execution flow becomes:
1. LLM calls schedule_task tool
2. API creates persistent task record
3. Delayed queue job is created
4. Worker processes the job later
5. Worker updates persistent task state
This architecture gives you:
- auditability
- recoverability
- observability
- replay capability
- debugging visibility
You can always reconstruct queue state from persistent storage if needed.
How LLM-Based Scheduling Actually Works
The scheduling flow usually looks like this:
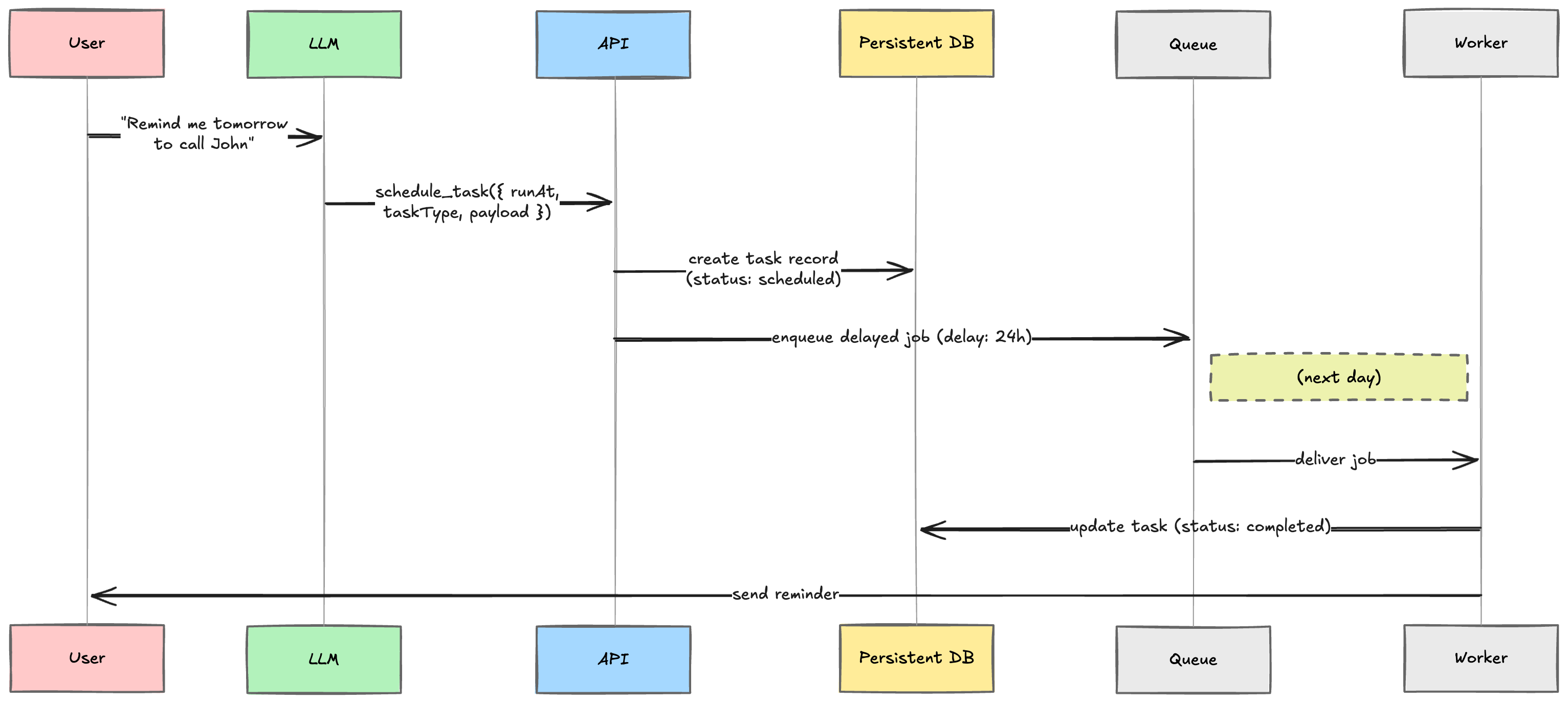
This is one of the cleanest ways to introduce asynchronous behavior into AI agents.
The LLM does not directly manage timers.
It only decides intent.
Infrastructure handles execution reliability.
Shared Scheduling Infrastructure Becomes Very Useful
Now imagine you have:
- web AI assistant
- voice AI assistant
- CRM AI assistant
And all of them need scheduling.
Duplicating scheduling logic across services becomes messy very quickly.
This is where shared scheduling infrastructure starts making a lot of sense.
Instead of every service implementing:
- task schemas
- scheduling APIs
- queue integration
- retry logic
- persistence logic
- audit history
you centralize scheduling tools behind a shared service or MCP server.
Then all agents can use the same tools:
schedule_task
cancel_task
list_tasks
reschedule_task
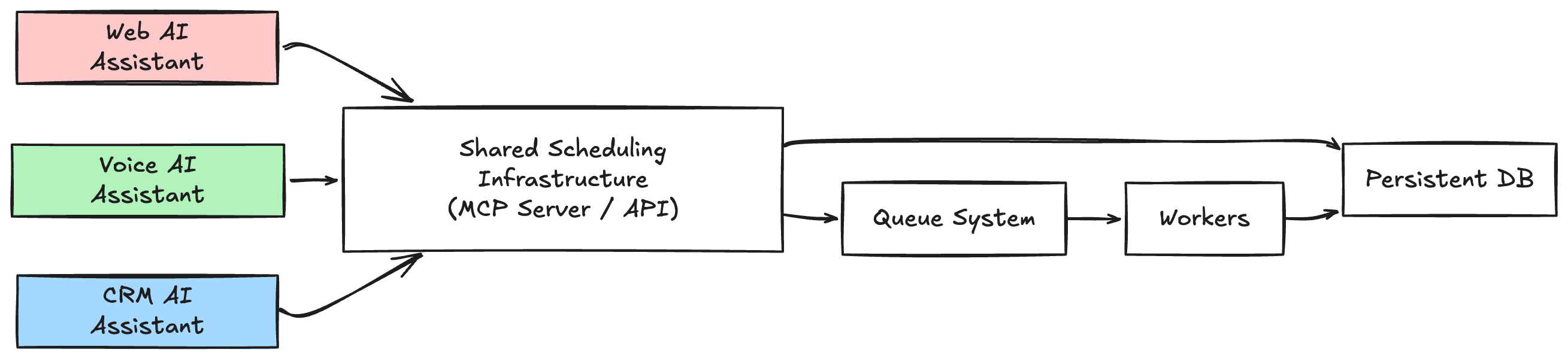
This creates:
- consistent behavior
- centralized observability
- unified persistence
- reusable infrastructure
- easier maintenance
Especially important when AI agents live in separate services.
Better UX - Tool Calls as UI Widgets
One subtle but powerful UX improvement:
Do not return plain confirmation text.
Instead of:
"Okay, I will remind you tomorrow."
render the tool call itself as a UI widget.
For example:
Reminder Scheduled
------------------
Task: Call John
Time: Tomorrow 9:00 AM
Timezone: America/Edmonton
Status: Scheduled
This creates several advantages:
- users trust the system more
- scheduled actions become visible
- users can edit/cancel tasks
- agent actions feel tangible
- task history becomes inspectable
This pattern is becoming increasingly common in modern AI products.
The AI is no longer just generating text.
It is operating a visible system.
Choosing Between Timer-Based Scheduling and Distributed Queues
Both approaches are valid.
The correct choice depends on the operational model of your AI agent.
Timer-based schedulers can be an excellent solution when:
- the agent runs locally
- the system is single-user
- infrastructure simplicity matters
- you want full scheduling control
- distributed coordination is minimal
Distributed queue systems become extremely attractive when:
- multiple pods/workers exist
- the system serves many users
- workloads are distributed
- execution guarantees matter
- retries and recovery become critical
- operational observability matters
The key distinction is not "toy vs production".
The distinction is:
who is responsible for distributed coordination complexity
With timer-based schedulers, your application owns that complexity.
With queue systems, infrastructure owns more of it.
My Recommendation for Production AI Agents
For production multi-tenant AI systems:
- use persistent task storage
- use distributed workers
- treat queues as operational infrastructure
- do not treat queues as the source of truth
- avoid implementing distributed locking unless you intentionally want that control
- centralize scheduling tools if multiple agents exist
- expose scheduled tasks as UI state, not hidden infrastructure
At the same time, timer-based schedulers remain a valid and proven architectural approach in the right environment.
Especially when the agent operates locally, serves a single user, or intentionally optimizes for low infrastructure overhead.
The important part is understanding the tradeoffs before the system scales.
Because background scheduling eventually stops being "just a feature".
It becomes part of your distributed systems architecture.
Summary
Building background task infrastructure for AI agents is ultimately a distributed systems architecture decision.
Timer-based schedulers and queue-based workers are both valid approaches. The important part is understanding the operational tradeoffs before the system scales.
A few quick notes before wrapping up:
- Queue systems solve distributed coordination, not just scheduling
- Persistent storage should remain the source of truth
- Queue infrastructure should be treated as ephemeral operational state
- Multi-worker environments introduce an entirely different class of problems
- AI agents increasingly need durable asynchronous workflows
- Scheduling becomes much easier when centralized behind shared infrastructure
Projects like OpenClaw Github show that timer-based schedulers can work extremely well when the agent serves a single user locally and avoids much of the distributed systems overhead that remote multi-tenant AI platforms face.
For distributed production systems though, queue-backed workers remain one of the cleanest ways to build reliable background execution.
If you liked this article, you might also enjoy my previous AI-related post: AI Agent UI Widgets - Why I Chose a Custom Implementation Over CopilotKit, AI SDK, LangChain, and Google A2UI
Until next time and happy coding! 🧑💻