How to Build a Chatbot With Your Own Data: A Practical Guide to Chatbot System Design


So, your team just asked you to build a chatbot that actually knows about your company's internal data — and you're staring at a blank screen wondering where to begin?
Been there. And in this post, I’ll walk you through how I would approach building a chatbot with your own data, step-by-step — using a simple but powerful chatbot system design.
🔍 What Are We Building?
We’re building a chatbot that not only understands general knowledge, but can also answer company-specific questions using your internal data: documents, product info, processes, FAQs, and more.
🧠 High-Level Chatbot System Design
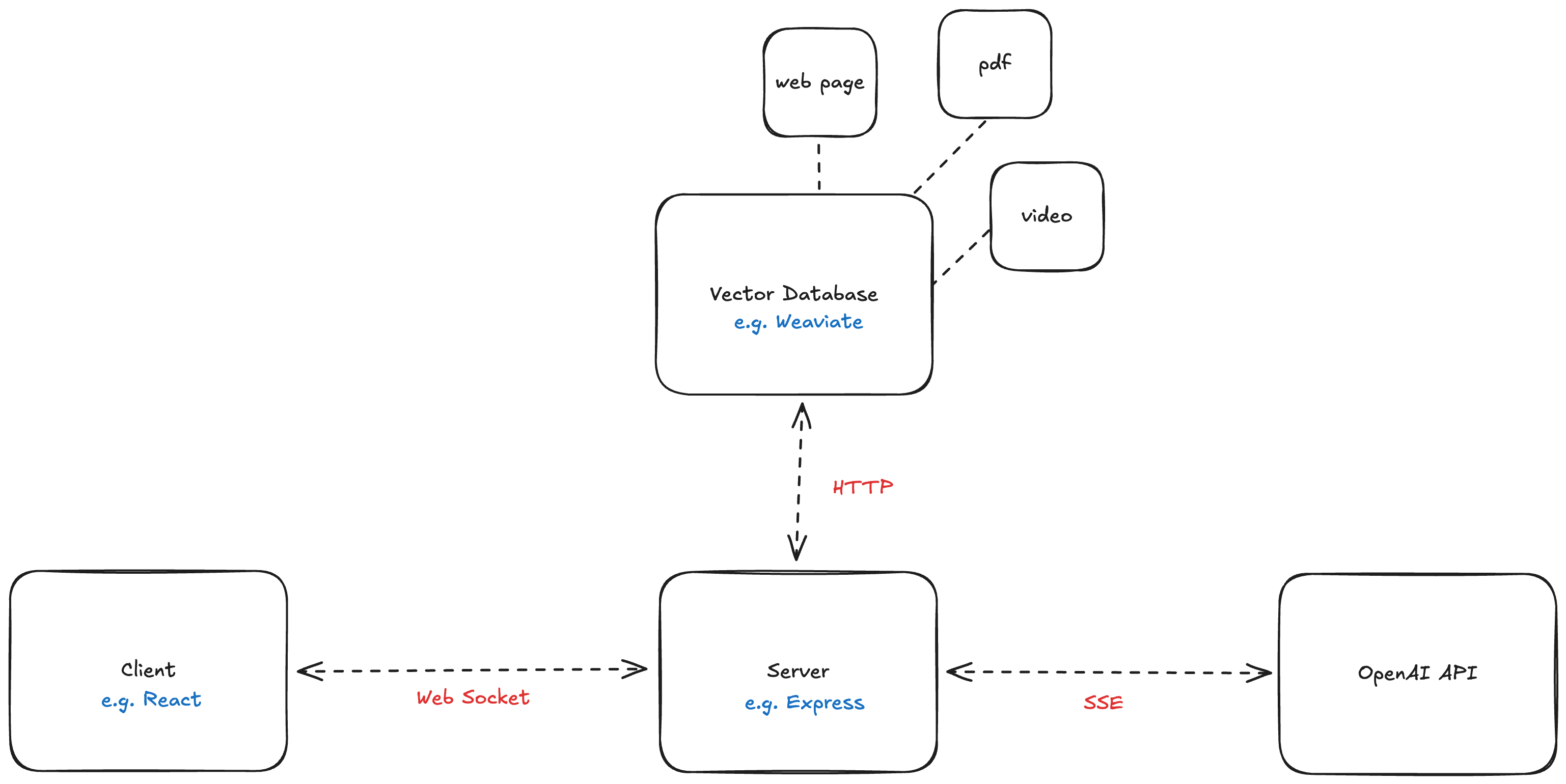
Here’s what makes up our AI chatbot:
- Client (React UI) – Where users chat with the bot.
- Server (Express) – The middleman, orchestrating the data flow.
- Vector Database (Weaviate) – Where your company’s data lives, in a searchable format.
- LLM API (OpenAI) – The “brain” that crafts responses.
So how do these parts work together to let users query your data?
Let’s start simple.
🤖 Step 1: Build a Chatbot Without Your Own Data
To get the basics down, let’s begin with a general chatbot — one that uses only the LLM’s built-in knowledge.

The flow is simple:
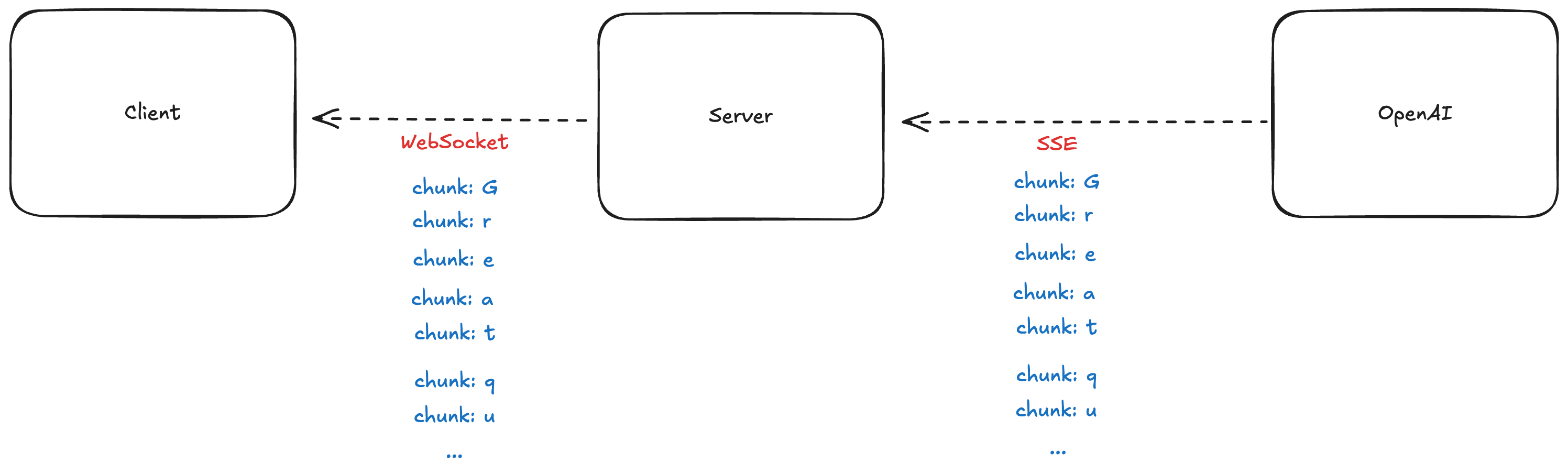
- The user asks a question.
- The client sends it to the server using WebSocket (we use sockets so responses can stream in real-time).
- The server forwards the message to the LLM (e.g. OpenAI).
- The LLM replies, chunk by chunk.
- The client displays the answer as it arrives — creating that “typing as you go” feel.
🤔 What’s an LLM?
LLM stands for Large Language Model. Think of it as the brain 🧠 of your chatbot.
You give it some input — like a user question — and it responds with natural-sounding text. The magic is in how it predicts the next word based on the context you give it.
When you're building a chatbot without your own data, the LLM responds using its pre-trained knowledge, like a supercharged autocomplete.
But there’s a catch: it only knows what it was trained on. So if you ask it something specific about your company — like details about the new product you are working on — it won't have the answer.
That's where your own data comes in.
📁 Step 2: Build a Chatbot With Your Own Data
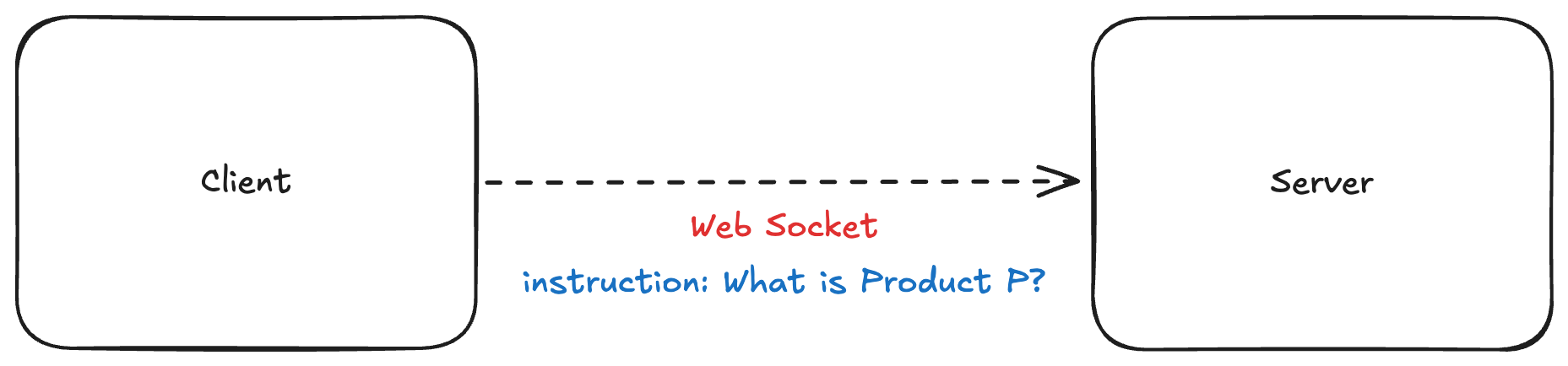
Let’s say your user asks about Product P — a top-secret project you just launched internally. The LLM has zero knowledge of it.
That’s when we bring in the magic sauce: the Vector Database.
🧬 What’s a Vector Database?
Think of it as your company’s smart memory bank. It stores all kinds of internal data — PDFs, Notion docs, videos, you name it — but in a way that can be searched semantically, not just by keywords.
Here’s how it works:
- Convert your internal data into embeddings using
OpenAIEmbeddings. - Store those embeddings in
Weaviate(or another vector DB). - When a user asks something, convert their question into an embedding.
- Search the vector DB for documents that are semantically similar.
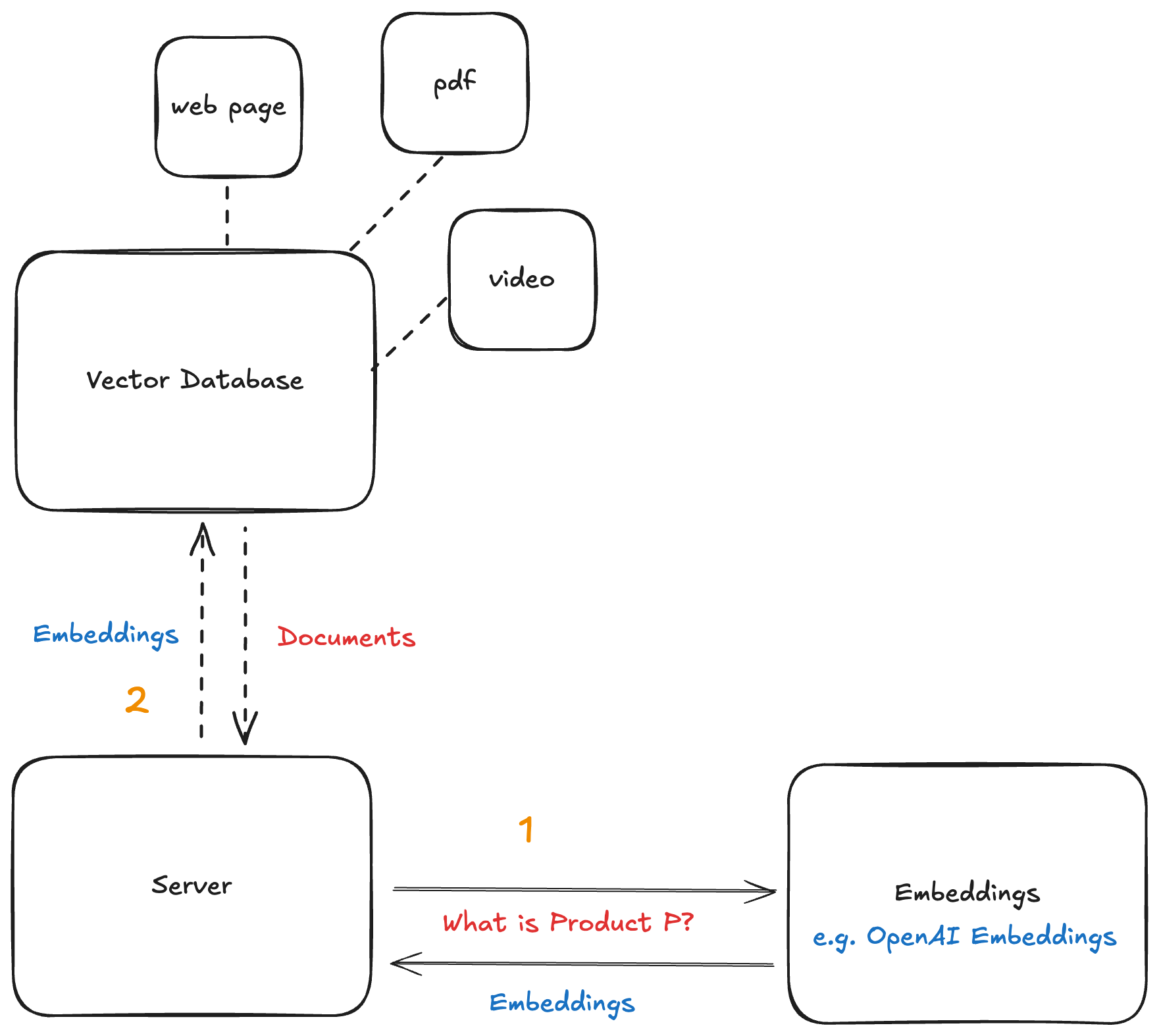
For example, if a user asks about “Project Management,” and you have a PDF called SCRUM Best Practices, the database will likely return it — because the two are conceptually close.
Then you:
- Take those matching documents.
- Add them to your prompt.
- And send that enhanced prompt to the LLM.
This gives the LLM the context it needs to answer accurately — using your own data.

🧪 Tech Stack to Build a Chatbot With Own Data
📦 Tools:
- Client - React
- Server - Express
- Vector DB - Weaviate
- Embeddings - OpenAIEmbeddings
- LLM - OpenAI API
Let’s make this real with a solid tech stack.
🛠 Setup:
- Use
OpenAIEmbeddingsto convert your internal files (PDFs, web pages, etc.) to embeddings. - Store those embeddings in
Weaviate. - Establish a
WebSocketconnection between yourReactclient andExpressserver. - Get an
OpenAI APIkey.
🔁 Flow:
- User submits a question in the
Reactchat. - Express receives it via
WebSocket. - Express queries
Weaviatefor relevant documents. - It then sends both the user’s question and those docs to
OpenAI API(usingstream: true). - Each token (piece of the answer) is streamed back to
ReactoverWebSocketfor real-time typing.
🧵 Wrapping Up
We’ve covered the journey from building a basic chatbot to designing a smart one that can:
- Search your internal data using semantic embeddings,
- Incorporate that data into the LLM’s context,
- And deliver accurate, contextual answers to your users.
This is the essence of how to build a chatbot with your own data — and the core of modern chatbot system design.
Thanks for reading! 🙌 If you found this helpful, you might also like:
Ever Heard of This Mysterious Thing Called RAG?
Until next time — happy building! 🚀