A Practical Guide to Multi-Agent RAG Design


A Practical Guide to Multi-Agent RAG Design
How I designed a multi-agent retrieval system and what I learned along the way
Many examples of RAG systems on the internet focus on a single agent: one model that reads your prompt, looks up some documents, and produces an answer. That setup works well for simple tasks, but as soon as your product grows, you start hitting real limitations.
Over the past months I have been implementing a multi-agent RAG architecture for our product. This article explains the actual design decisions, patterns, pitfalls, and improvements that came out of that work. My goal is to give beginners and non-expert technical readers a clear understanding of how multi-agent RAG works in the real world.
Why a Single-Agent RAG Starts Breaking Down
If your system needs to answer a simple factual question, a single agent is enough. But most real products need more than that. You might need:
- Multiple agents pursuing different goals (customer success agent, code review agent, developer agent)
- Access to different domains of knowledge (customer data, product docs, business rules)
- Internal safety checks
- Specialized formatting (JSON, UI components, decision trees)
A single agent becomes a bottleneck because it tries to solve everything at once. It becomes harder to tune, harder to debug, and harder to trust.
This is where a multi-agent RAG structure becomes valuable. All your agents still have access to the company data, but they use it differently to pursue different goals.
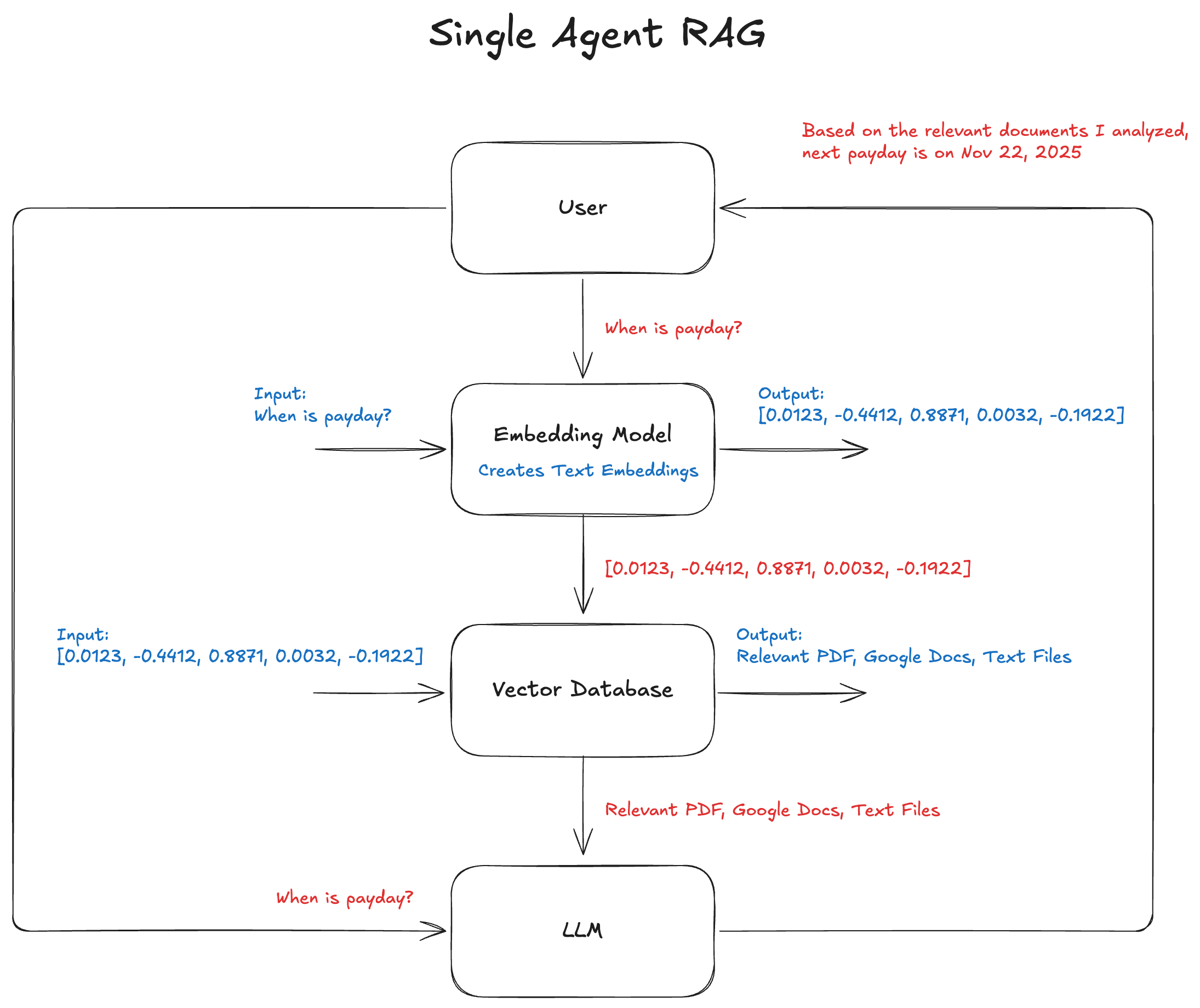
See the single-agent RAG system diagram below.
What Multi-Agent RAG Actually Means
At its core, a multi-agent RAG system it is a structured pipeline where different agents have different responsibilities. Think of it like a small team:
- One agent listens to the user and decides what needs to happen
- Some agents specialize in answering certain types of questions
- A final agent may refine or validate the output before returning it
Each step is isolated, easier to debug, and easier to improve individually.
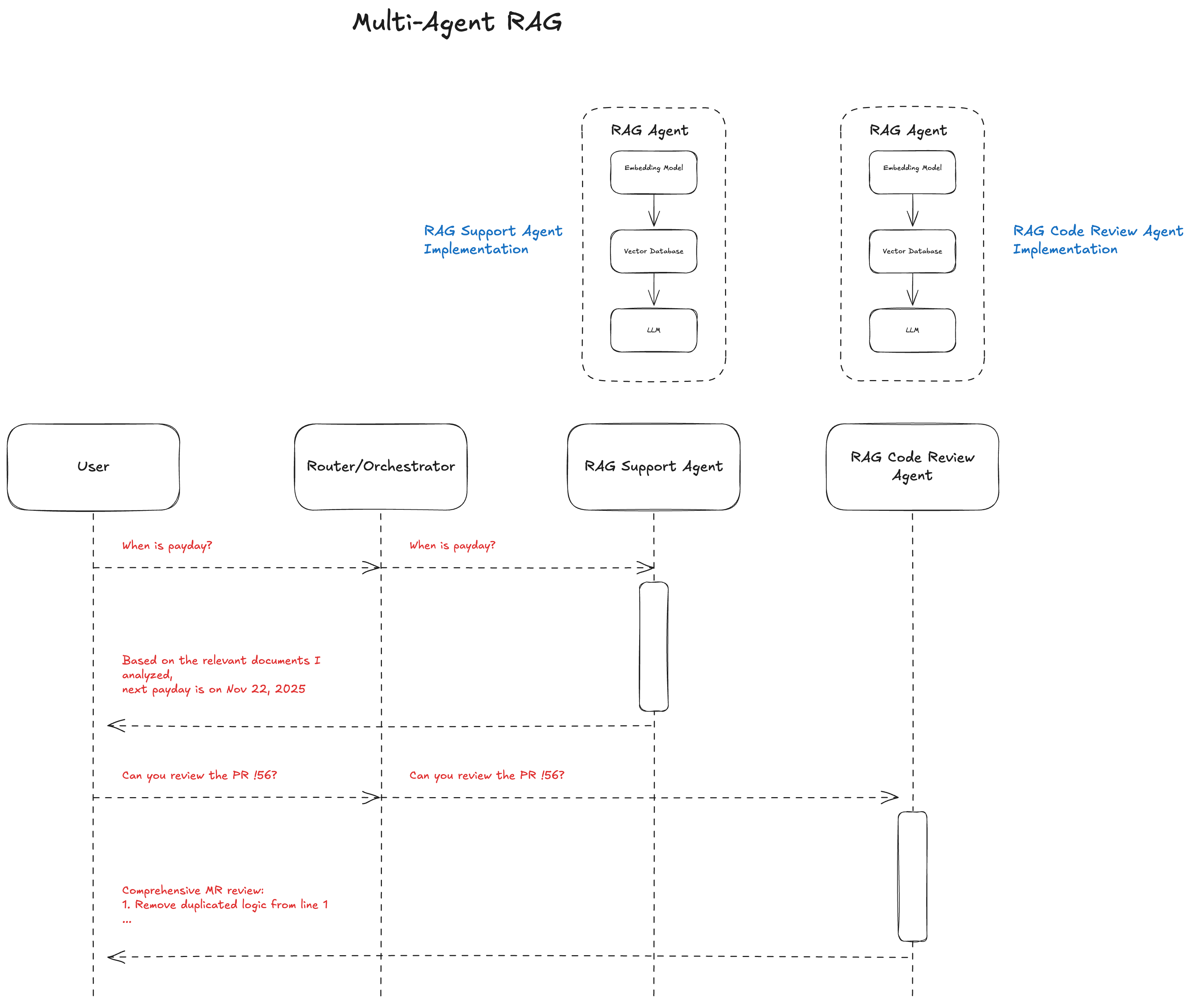
See the multi-agent RAG system diagram below.
The 5 Core Components of a Multi-Agent RAG System
Below is the structure that worked best for our application. You can adapt it depending on your domain.
1. The Router
This is the entry point. It reads the user prompt and decides where to send it.
It is not trying to answer the question. Instead, it predicts intent.
A few examples:
- Instruction or how-to question
- Pricing question
- Troubleshooting
The router's goal is to keep the rest of the system simple.
2. The Retrieval
This layer handles all the knowledge work.
If you refer to the singe-agent RAG system diagram above, it's the Embedding Model + Vector Database layers. After the user question was routed to a specific agent, it's time to fetch all the context (pdf documents, articles, Google Doc document) that exist in our company database. This allows the agent to tap into our company operation processes and guidelines.
What it does:
- Expands the query into search-ready versions
- Chooses the right vector index
- Selects search parameters (top_k, filters, semantic vs keyword)
- Retrieves and ranks candidates
Instead of mixing retrieval logic inside every other agent, this central agent keeps it consistent.
ℹ️ In the multi-agent RAG systems, every agent has it's own retrieval layer.
3. The Domain
If you refer to the single-agent RAG system diagram above, it's the LLM layer. It knows a particular domain of the problem it solves and a particular reasoning style.
It's the LLM and the LLM configuration prompt that comprise this layer. The configuration prompt is the instruction you give the LLM to give it a persona and to help it understand exactly what problems it solves.
Configuration Prompt Example:
You are the Customer Success Agent.
Your role is to help users understand and succeed with the product by providing clear, empathetic, and actionable guidance. You focus on solving problems, reducing user friction, and ensuring they feel supported and confident.
Domain Examples:
- Customer Support agent
- Code Review agent
- Software Developer agent
Domain agents are easier to tune because they handle a narrow slice of knowledge.
This layer is also responsible for calling tools so the LLM can interact with third-party services and systems. This article does not cover tools, so it might be a good idea to check the OpenAI tools guide if you haven't heard about this concept before.
5. The Output Refiner
This layer is optional, but it's very effective if you need to validate your answers before responding to the user. The diagrams above skip this layer, but it's important when working with sensitive data like dealing with health-related and financial advices.
This final layer checks for:
- Tone
- Accuracy
- Missing steps
- Hallucinations
It might be surprisingly good at catching issues created upstream.
How the Whole Flow Works Together
Here is a simplified example:
- User: "When is next payday?"
- Router: routes to the general company knowledge agent
- Retrieval Layer: fetches docs on financial policies and important updates from the financial department
- Domain Layer: analyzes the situation and writes step-by-step reasoning using the relevant context from the retrieval layer
- Output Refiner: rewrites in a clear and accurate answer
- Final answer is sent back to the user
Real Lessons Learned While Building It
1. Routing is more important than fancy agents
The router agent determines the entire experience. Bad routing is the fastest way to get irrelevant or confusing answers.
2. Your domain agents should be dumb, not clever
Keep them focused on one task. The more narrow the domain, the easier it is to tune and monitor. If there's a need to solve more problems, add more agents that are focused on solving these problems.
3. Add a final step for refinement (if dealing with important domains)
Even a good multi-agent pipeline occasionally produces messy outputs. A refiner agent fixes tone and accuracy.
This is crucial if giving health-related or financial advices.
How Beginners Can Experiment With Multi-Agent RAG
If you are just starting:
- Begin with 2 agents: a general answerer agent and a code review agent
- Add router: which selects an agents to delegate the problem to
- Add retrieval layer for each agent
- Add the configuration prompt for each agent and clearly define persona and give it clear understanding of the problem it should solve
- Add a refiner when you want consistently polished answers (mostly for practice)
Closing Thoughts
Multi-agent RAG is about reducing complexity by splitting responsibilities in a predictable and scalable way. The result is a system that is easier to reason about, safer to run in production, and more consistent from the user's perspective.
The biggest benefit I noticed after implementing multi-agent RAG is this: each part of the system became easier to test and easier to improve without breaking everything else.
If your RAG system is starting to feel too chaotic or too unpredictable, a multi-agent approach might be the next natural step.
If you liked this article, consider checking another RAG-related article: Ever Heard of This Mysterious Thing Called RAG?
Until next time — happy coding! 🧑💻